Automatic data-discovery¶
The TimeSeries.fetch_open_data() method is only able to download
GW strain data from those datasets exposed through the GWOSC API;
this notably does not include the Auxiliary Channel Three Hour Release, or strain data
for any events or observing runs not yet published.
In addition, the GW strain data make up only a tiny fraction of the ‘raw’ output of a gravitational-wave detector, which includes in excess of 100,000 different ‘channels’ (data streams) from sensors and digital control systems that are used to operate the interferometer and diagnose measure performance.
The full data set for each detector is archived at the relevant observatory
and is made freely available to all registered collaboration members.
A discovery service called gwdatafind is provided at each location to
simplify discovering the file(s) that contain the data of interest for any
research.
These data are also made available remotely using NDS2, which enables sending data directly over a network to any location. This is used for both the full proprietary data (which requires an authorisation credential to access) and also the Auxiliary Channel Three Hour Release (which is freely available).
TimeSeries.get()¶
Additional dependencies: FrameCPP or NDS2
GWpy provides the TimeSeries.get() method as a one-stop interface
to all automatically-discoverable data hosted locally at an IGWN
computing centre, or available remotely.
How it works¶
Without any customisation, TimeSeries.get() will attempt to locate
data ‘by any means necessary’; in practice that is
if the
GWDATAFIND_SERVERenvironment variable (or legacyLIGO_DATAFIND_SERVERvariable) points to a server URL, usegwdatafindto identify which data set includes the channel(s) requested, then locate the files for that data set, and then read them,if that doesn’t work (for any reason), loop through the NDS2 servers identified in the
NDSSERVERenvironment variable to see if they have the data – if theNDSSERVERvariable isn’t set, guess which NDS2 server(s) to use based on the interferometer whose data was requested.
Regarding channel names
To use TimeSeries.get(), you need to know the full name of the
data channel you want, which is often not obvious.
The Auxiliary Channel Three Hour Release includes a link to a full listing of all
included channels.
For the full proprietary data set, the IGWN Detector
Characterisation working group maintains a record of the most relevant
channels for studying a given interferometer subsystem.
Example¶
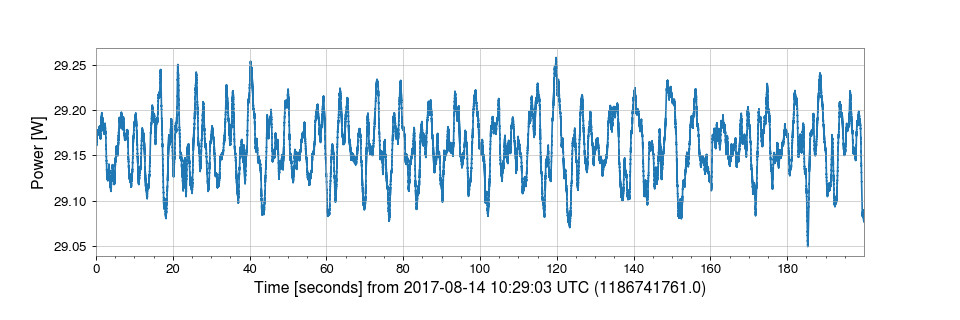
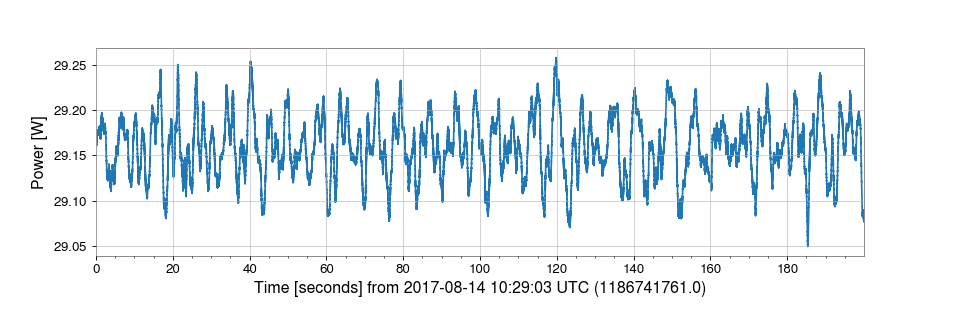
For example, to channel that records the power incident on the input mode cleaner (IMC) at LIGO-Hanford, is called:
H1:IMC-PWR_IN_OUT_DQ
and we can use TimeSeries.get() to ‘get’ the data for that
channel by specifying the special GWOSC NDS2 server url using the
host keyword:
>>> from gwosc.datasets import event_gps
>>> from gwpy.timeseries import TimeSeries
>>> gps = event_gps("GW170814")
>>> start = int(gps) - 100
>>> end = int(gps) + 100
>>> data = TimeSeries.get("H1:IMC-PWR_IN_OUT_DQ", start, end, host="losc-nds.ligo.org")
>>> plot = data.plot(ylabel="Power [W]")
>>> plot.show()
(png)
{kind=link}
Proprietary datasets¶
All data archived at an IGWN computing centre are identified by a data
set ‘tag’, which identifies which data are contained in a given gwf
file(s).
By default, as described, TimeSeries.get() will search through all
available data to find the correct files to read, so this may take a
while if the server has knowledge of a large number of different datasets.
If you know the dataset name – the tag associated with files containing your
data – you can pass that via the frametype keyword argument to
significantly speed up the search.
The following table is an incomplete, but probably OK, reference to which
dataset (frametype) you want to use for file-based data access:
Dataset (frametype) |
Description |
|---|---|
|
The GEO-600 data, including calibrated strain h(t) |
Dataset (frametype) |
Description |
|---|---|
|
All auxiliary channels, stored at the native sampling rate |
|
Second trends of all channels, including
|
|
Minute trends of all channels, including
|
|
Strain h(t) and metadata generated using the real-time calibration pipeline |
|
Strain h(t) and metadata generated using the
off-line calibration pipeline at version |
|
4k Hz Strain h(t) and metadata as released by GWOSC for the O2 data release |
|
16k Hz Strain h(t) and metadata as released by GWOSC for the O2 data release |
Dataset (frametype) |
Description |
|---|---|
|
All auxiliary channels, stored at the native sampling rate |
|
Second trends of all channels, including
|
|
Minute trends of all channels, including
|
|
Strain h(t) and metadata generated using the real-time calibration pipeline |
|
Strain h(t) and metadata generated using the
off-line calibration pipeline at version |
|
4k Hz Strain h(t) and metadata as released by GWOSC for the O2 data release |
|
16k Hz Strain h(t) and metadata as released by GWOSC for the O2 data release |
Dataset (frametype) |
Description |
|---|---|
|
All auxiliary channels, stored at the native sampling rate |
|
Strain h(t) and metadata for Observing run 3
( |
|
4k Hz Strain h(t) and metadata as released by GWOSC for the O2 data release |
|
16k Hz Strain h(t) and metadata as released by GWOSC for the O2 data release |
Not all datasets are available everywhere
Not all datasets are available from all datafind servers. Each LIGO Lab-operated computing centre has its own datafind server with a subset of the available datasets.
LIGO trend data¶
The LIGO observatories produce second- and minute- trends of all channels
automatically, and store them in the {H,L}1_T (second) and {H,L}1_M
(minute) datasets.
However, the channels in each trend type have the same names, so
TimeSeries.get() doesn’t know how to distinguish between the two
different trends when given only the channel name.
To get around this you can directly specify (e.g.) frametype="H1_T"
(for the LIGO-Hanford second trends) in your TimeSeries.get()
method call, or you can use a suffix in the channel name:
Trend type |
Dataset |
Suffix |
|---|---|---|
second |
|
|
minute |
|
|
e.g.
>>> TimeSeries.get("L1:IMC-PWR_IN_OUT_DQ.mean,s-trend", 1186741850, 1186741870)
will specifically access the second trends of power incident on the LIGO-Livingston IMC.
TimeSeriesDict.get()¶
TimeSeries.get() can only retrieve data for a single channel at a time.
Looping over a list of names to get data for many channels can be very slow,
as each individual call will have to discover and read/download the data for
each channel individually.
The TimeSeriesDict.get() method enables retrieval of multiple channels
in a single call, for a single (start, stop) time interval, greatly
reducing the I/O overhead.
To access data for multiple channels in this way, just pass a list of names
rather than a single name.
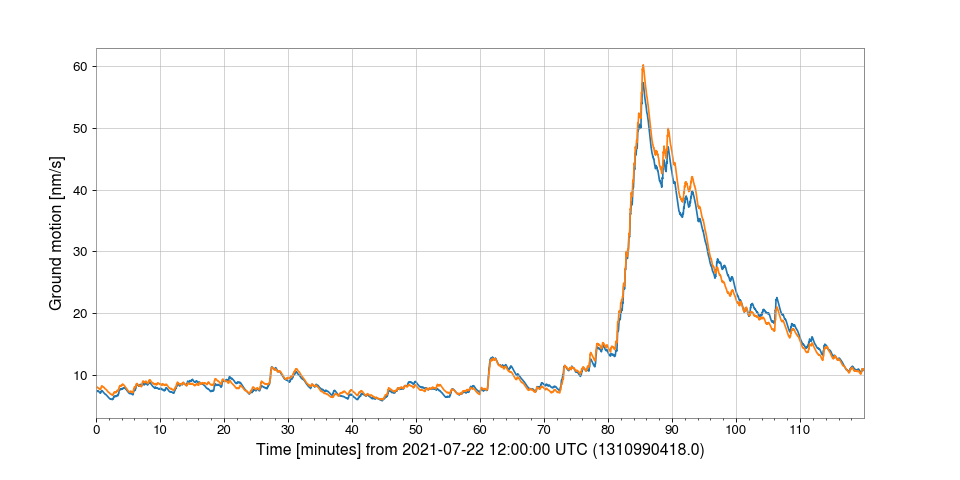
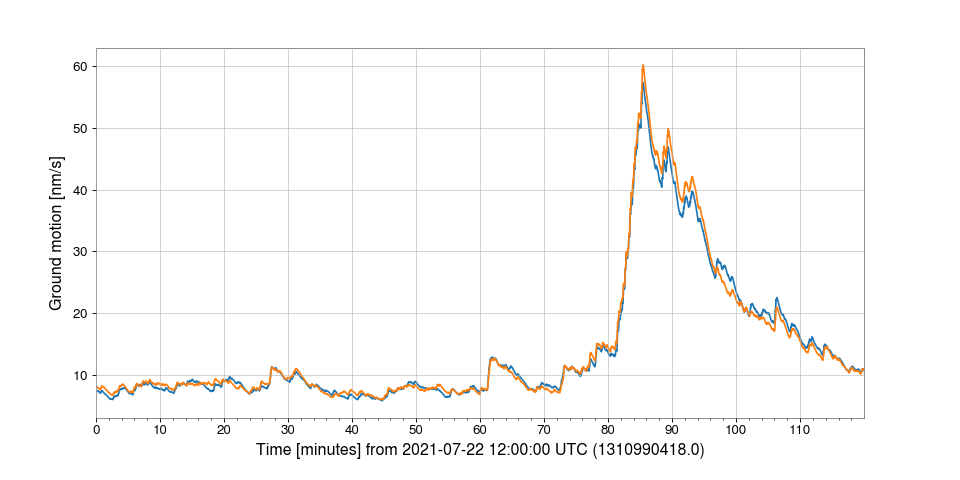
In this example we download the second trend (average) of ground motion in
the 0.03Hz-0.1Hz range at two locations of the LIGO-Hanford observatory:
Warning
This example uses proprietary data that are only available to members of the LIGO Scientific Collaboration and its partners.
>>> from gwpy.timeseries import TimeSeriesDict
>>> data = TimeSeriesDict.get(
... ["H1:ISI-GND_STS_ITMY_Z_BLRMS_30M_100M.rms,s-trend",
... "H1:ISI-GND_STS_ETMY_Z_BLRMS_30M_100M.rms,s-trend"],
... "July 22 2021 12:00",
... "July 22 2021 14:00",
... )
>>> plot = data.plot(ylabel="Ground motion [nm/s]")
>>> plot.show()
(png)
{kind=link}