Remote data access¶
The LIGO Laboratory archives instrumental data in GWF files hosted on the LIGO Data Grid (see Automatic data-discovery for more details), however, remote access tools have been developed to simplify loading data. GWpy provides two methods for remote data access, one for public data releases, and another for authenticated access to the complete data archive:
Method |
Restricted? |
Description |
|---|---|---|
public |
Fetch data from LIGO Open Science Center (LOSC) |
|
LIGO.ORG |
Fetch data via local disk or NDS2 |
Open data releases¶
The LIGO Open Science Center hosts a large quantity of open (meaning publicly-available) data from LIGO science runs, including the full strain record for the sixth LIGO science run (S6, 2009-2010) and short extracts of the strain record surrounding published GW observations from Advanced LIGO.
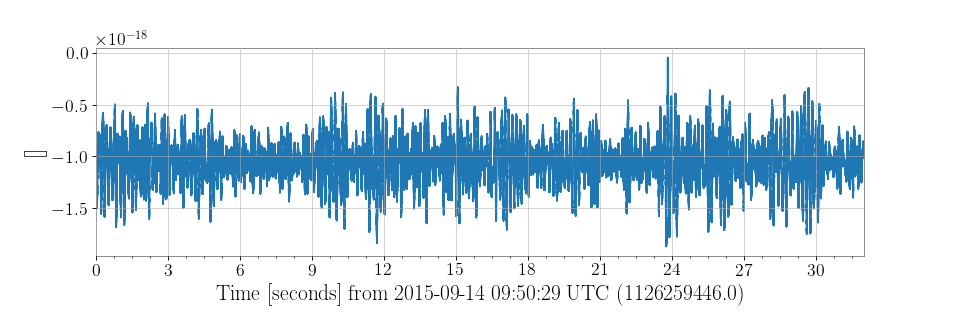
To fetch 32 seconds of strain data around event GW150914, you need to give the prefix of the relevant observatory ('H1' for the LIGO Hanford Observatory, 'L1' for LIGO Livingston), and the start and end times of your query:
>>> from gwpy.timeseries import TimeSeries
>>> data = TimeSeries.fetch_open_data('L1', 1126259446, 1126259478)
Above the times are given in GPS format, but you could just as easily use a more readable format:
>>> data = TimeSeries.fetch_open_data('L1', 'Sep 14 2015 09:50:29', 'Sep 14 2015 09:51:01')
You can then trivially plot these data:
>>> plot = data.plot()
>>> plot.show()
(png)
{kind=link}
For more details on plotting a TimeSeries, see Plotting time-domain data.
Note
TimeSeries.fetch_open_data() accepts the keyword cache, which,
wnen set to True will store the downloaded data so that repeated requests
for a given URL result in only one download.
The GWPY_CACHE environment variable can be set (GWPY_CACHE=1)
to automatically set cache=True for all open data downloads.
Restricted full data archives¶
Additional dependencies: nds2
Members of the LIGO Scientific Collaboration or the Virgo Collaboration can access the full raw and processed data archived via an authenticated remote protocol called NDS2.
In this case, the TimeSeries.get() method can be used to download data for any one of thousands of archived data channels.
Note
Access to data using the nds2 client requires a Kerberos authentication ticket.
This can be generated from the command-line using kinit:
$ kinit albert.einstein@LIGO.ORG
where albert.einstein should be replaced with your own LIGO.ORG identity.
If you don’t have an active kerberos credential at the time you run TimeSeries.get, GWpy will prompt you to create one.
For Advanced LIGO the calibrated strain data channel is called GDS-CALIB_STRAIN, so to fetch H1 strain data for the same period as above:
>>> data = TimeSeries.get('H1:GDS-CALIB_STRAIN', 1126259446, 1126259478)
Authenticated collaborators also have access to the thousands of auxiliary channels mentioned above, for example running:
>>> gnd = TimeSeries.get('L1:ISI-GND_STS_ITMY_Z_DQ', 'Jan 1 2016', 'Jan 1 2016 01:00')
will return one hour of data from the vertical-ground-motion seismometer located near the ITMY vacuum enclosure at LIGO Livingston.
The TimeSeries.get method tries direct file access (using gwdatafind for file discovery) first, then falls back to using the Network Data Server (NDS2) for remote access.
If you want to manually use NDS2 for remote access you can instead use the TimeSeries.fetch method.